Simplify regex by decoupling it from your programming language
In this article:
You know what's awesome?! Regex is! I use it almost every day to search through my codebase, and occasionally to parse text input in my code. (If you're unfamiliar: regex, short for regular expression , is a powerful technique for searching large amounts of text using a specialized string of characters.)
But I've heard something surprising lately from many developers: "I hate regex". What?? Why would anyone say something so horrible about something that's so fun? I have a theory...
I'm going to go out on a limb here and make a bold claim: nobody hates regex, they just hate implementing it into whatever programming language they use (hear me out on this). Even with a perfect grasp of how regex works, it can be difficult to figure out what the regex is actually doing when sending it through a coding interface.
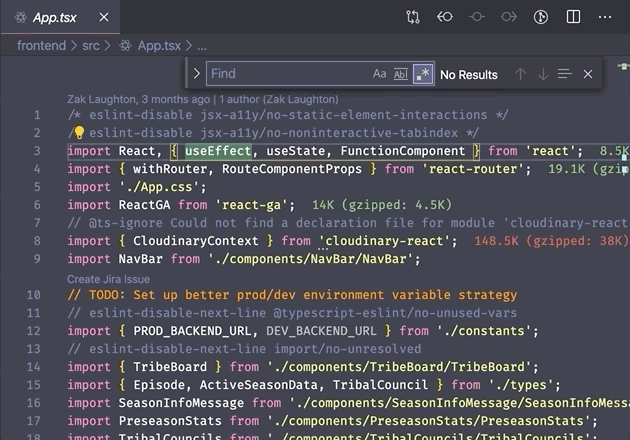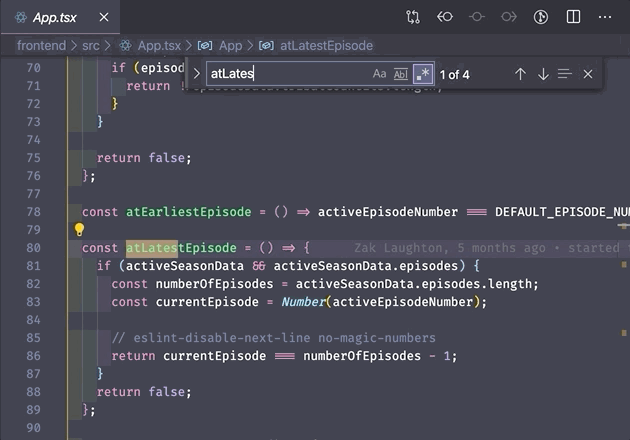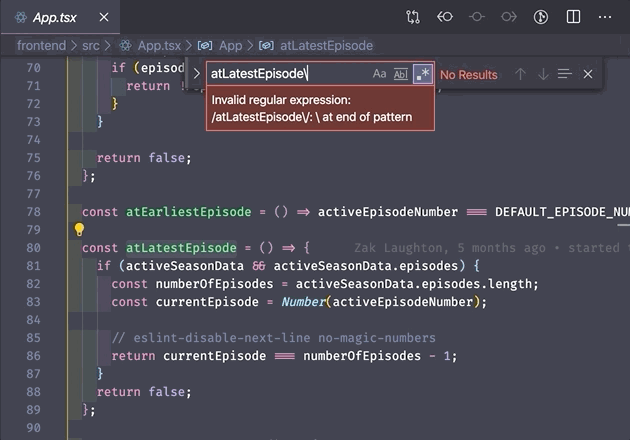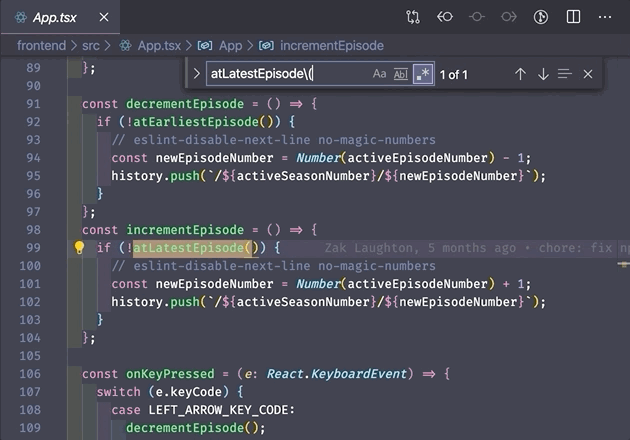
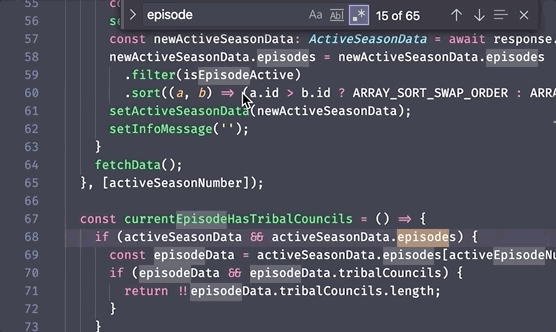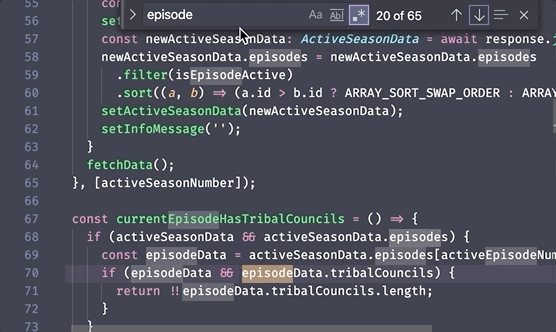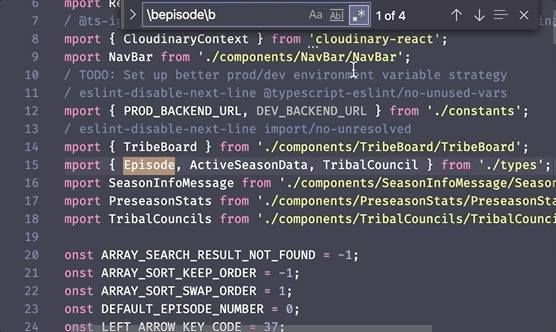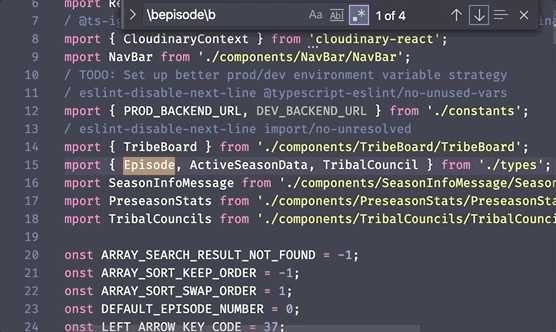
As an example, here's a nice easy search for the word episode using regex
in a text editor where we can easily see the results:
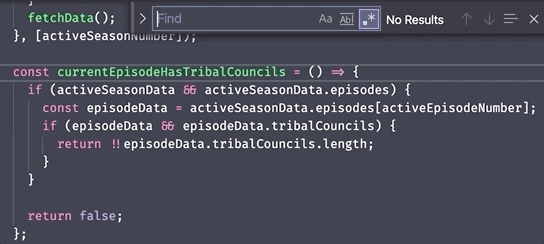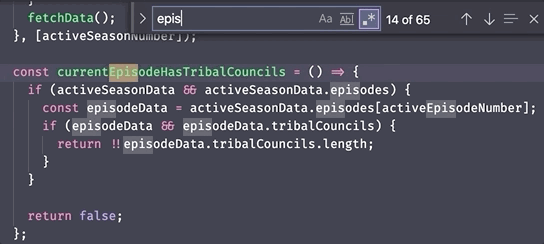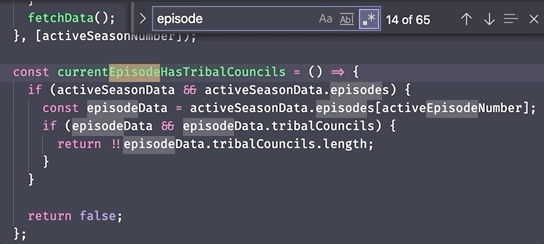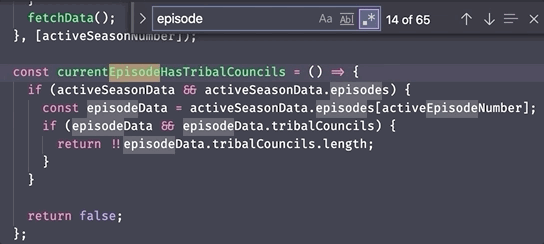
...but here's an example where we're searching for the same word in a myText variable using JavaScript regex functions:

Clearly, regex isn't the problem here! The problem is figuring out how to use regex in these dang functions! Hating regex because of confusing code implementation is like hating cake batter for burning your cake. And do you know who hates cake batter? Nobody. Cake batter is delicious.
So in this article, I'm going to focus on just eating the cake batter. I'm going to show you the powers of regex by using it to search code in a text editor, without the pesky implementation of a programming language. I'll show you how it's an essential tool to search your files, and hopefully teach you some new delicious tricks along the way to help when you do need to use it in your code.
Most useful regex notations
There are entire textbooks written on how to write regex queries, but you only need a few basics to start seeing some big results. Below I've listed the 4 regex notations I use most often to quickly narrow down large sets of text to a single snippet.
The examples below will be using Visual Studio Code, but most other code text editors such as Sublime and Atom have similar regex search functionality. If you're following along, you can open up a text search in your editor using Ctrl + F (on mac: ⌘ + F), or search all your files using Ctrl + Shift + F (on mac: ⌘ + Shift + F). Be sure the regex option (the one that looks like .*) is enabled, and the rest are disabled:

1. Simple text search
At its base functionality, it's important to remember that regex will just search regular ol' text. If you're searching for text that just has letters, numbers and spaces, just type the text as your query.
If there are any special characters or punctuation, add a backslash \ before the character. This is because many special characters have meaning in regex queries that changes the search behavior. Adding a backslash "escapes" the character and tells regex to just search for the character itself. Example: to search for a period, type \., to search for an opening parenthesis, type \(.
2. Wildcard .*
.* is a wildcard that matches any number of characters. Use it to match strings where you're not certain of some of characters in the middle.
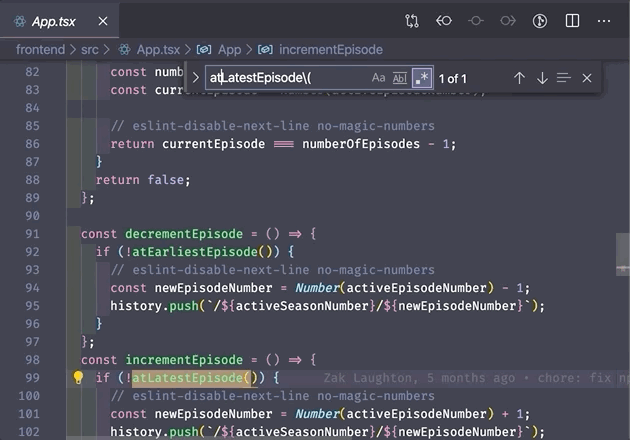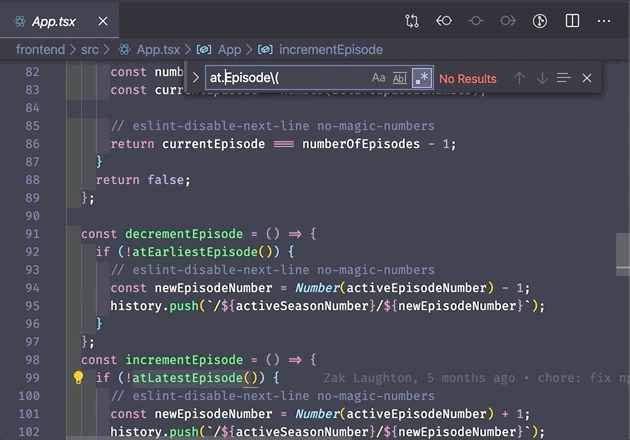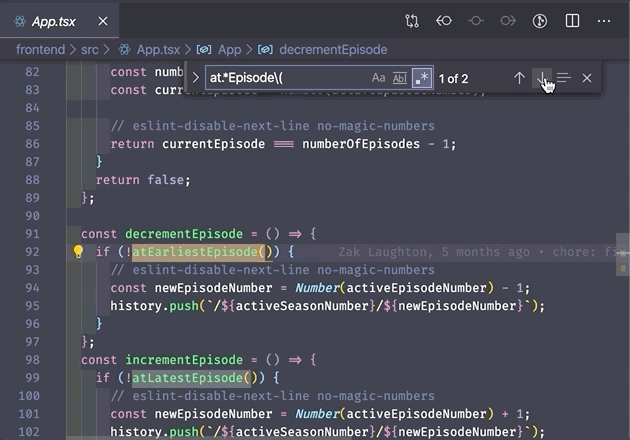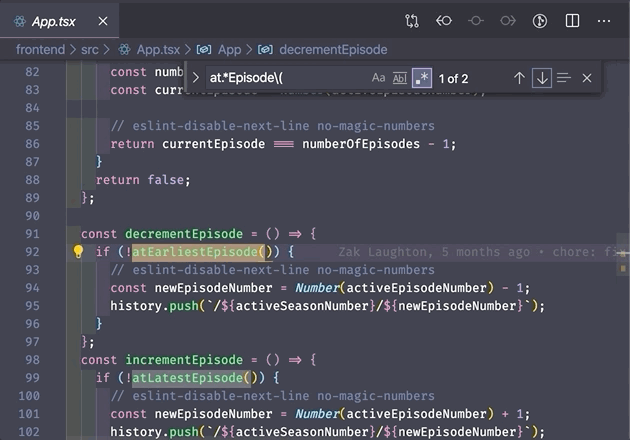
3. Capturing groups and backreferences ()
Capturing groups are a way to "capture" parts of your query with parenthesis to use for special functionality. On their own, these parenthesis won't impact the search results. For example, in the query (shab)la(go)o, both shab and go are captured groups, but the query will still match all instances of shablagoo in the text.
So why would you want to do this? A few reasons, but one of the most useful reasons in a text editor is to reference the text as a variable. Each capturing group is numbered by the order it appears and is assigned a numbered variable you can use to insert the captured text somewhere else (this is also known as a backreference).
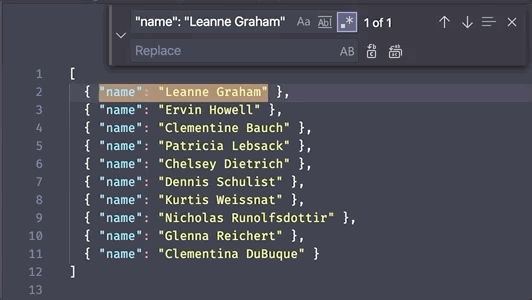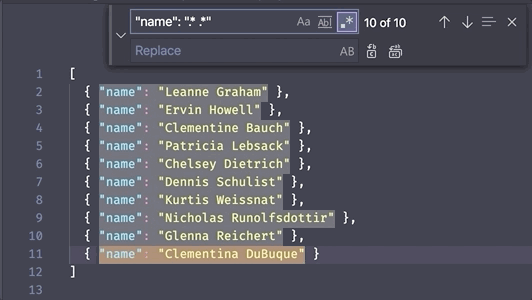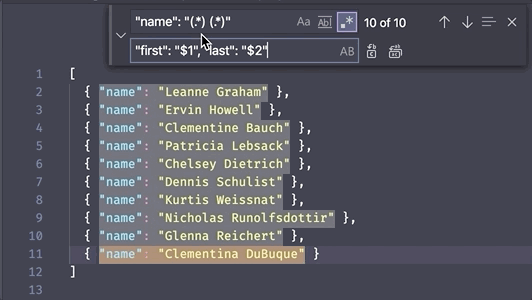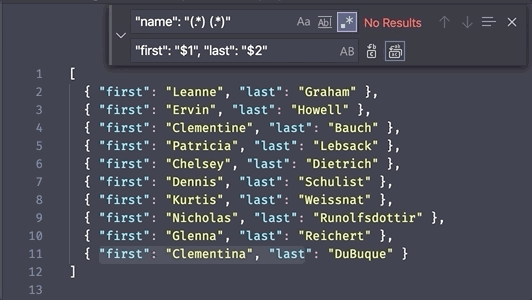
Where this gets really powerful in an editor is using these backreferences as search replacement variables. For example, if I search for (always)(blue), then set the replacement string to $2$1, then every occurrence of alwaysblue will be replaced with bluealways. This is because the first capturing group, always, is assigned to $1, and the second capturing group, blue, is assigned to $2.
This type of find and replace rearrangement is especially useful if you want to change the format of several records in a large dataset.
4. Word boundary \b
The last one I'm going to cover here is the word boundary, which I use all the time when searching short words in code. Let's say you want to find any time the word user shows up in your files. You can do a regex search of all files for user, but this will also include partial matches such as username, enduser, and obtuseRicearoni. That's where the word boundary comes in.
\b represents a boundary between a word and a non-word character. Or more simply – the edge of a word. (Note: a "word" character here means a letter, a number, or an underscore. A "non-word" character is everything else). This means you can search for \buser\b and it will only return instances of user that are not a part of a longer word or variable name. Pretty cool!
Wrap-up
That's it! These tips above can help optimize your processes, make it easier to search through large files, and hopefully help boost confidence when implementing regex in your own code.
When you do implement regex in your programming language of choice, I strongly recommend trying it out in a text editor first to ensure you've got the proper regex before adding the programming complications. There are also super helpful sites such as https://regexr.com/ and https://regexr.com/ that provide great cheatsheets and playgrounds for testing your regex.
What did I miss? Any other regex notations you love that I left out? Or any questions about using regex? Feel free to let me know in the comments!
Continue the conversation
Did this help you? Do you have other thoughts? Let's continue the discussion on Twitter! If you'd like to show your support, feel free to buy me a coffee. Thanks for reading!



Written by Zak Laughton, a full stack developer building tools to make life a little easier. Huge fan of JavaScript, React, GraphQL, and testing code.